Mask Your User Tokens
These days, fine-tuning large language models (LLMs) seems to be getting easier and easier. Multiple frameworks and resources now allow you to plug in your dataset and start fine-tuning. It’s not necessarily a bad thing that you can copy some code, swap in your dataset, fine-tune, and quickly create a model tailored to your needs. However, these default, one-click, or no-code approaches can sometimes obscure issues that might affect performance. My conclusion (OMG this is shocking): it’s crucial to understand how these models work, and not just run a script from the internet, no matter how popular the repository it’s taken from is.
A Case Study
I want to fine-tune an LLM on the Universal-NER/Pile-NER dataset. This is a NER-like dataset for generative models where every sample is a “conversation” in which a “user” asks the “assistant” for relevant tokens in the text. Here is an example sample:
{
"conversations": [
{"from": "human", "value": "Text: Q:\n\nHow can I restore my Unity?"},
{"from": "gpt", "value": "I've read this text."},
{"from": "human", "value": "What describes software in the text?"},
{"from": "gpt", "value": '["Unity"]'},
],
"id": "ner_4898",
}
As of May 2024, the most common way to fine-tune a conversational dataset is using transformers, peft, and trl. Huggingface added an abstraction called chat_template to format the conversation into a long string. Calling apply_chat_template on the previous sample with the ChatML format will create the following string:
<|im_start|>user
Text: Q:
How can I restore my Unity?<|im_end|>
<|im_start|>assistant
I've read this text.<|im_end|>
<|im_start|>user
What describes software in the text?<|im_end|>
<|im_start|>assistant
["Unity"]<|im_end|>
Once I have a dataset of text and not “conversations” I can use the transformer stack to finetune any model on it. Here are some popular really good examples:
- huggingface alignment-handbook
- NielsRogge mistral tuturial
- llam2 finetune with mlbonne great llm-course
All these tutorials are great. I can easily replace the dataset in any of them with Universal-NER and start training!
However, they all have one thing in common: the decoder model is trained to predict all tokens, including the tokens generated by the user part of the conversation!
Before going further heres a short reminder of what what autoregressive models train on.
Autoregressive Training Objective
Decoder models are trained to predict the next token. In the image bellow you can see than at timestamp i=4, the input is “the quick brown fox”, and the value we expect the model to predict is “jumps”.
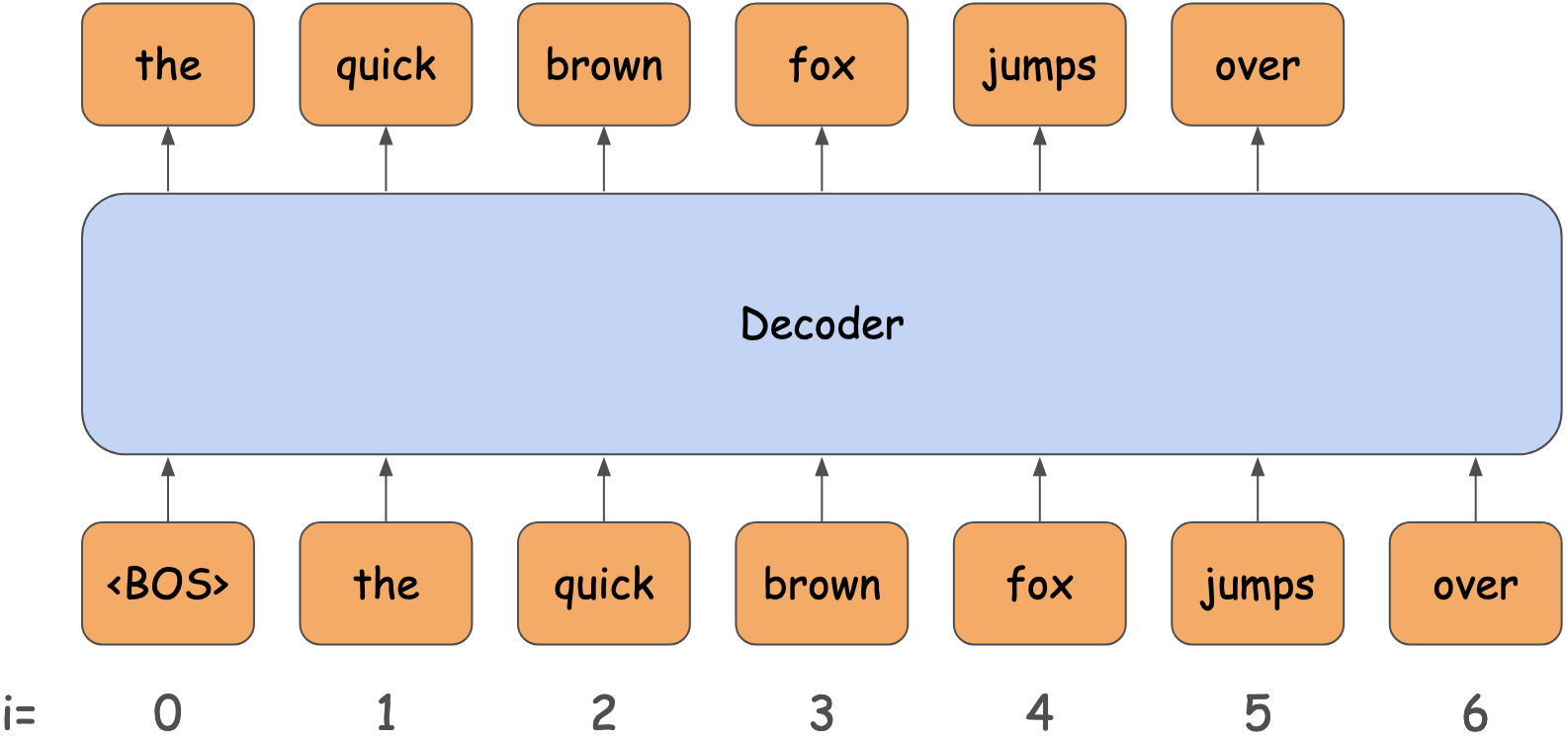
All decoder models in the transformers library have a <model_name>ForCausalLM class for this kind of autoregressive modeling. For example, Gemma has GemmaForCausalLM. If you look at its forward function, you will see it expects input_ids and labels. The forward function will take care of shifting the labels by 1.
While finetuning, we are expected to provide the input_ids and the labels. In the example tutorials above, this is done by either the:
In both cases, the labels are just a copy of the input_ids, which I’m trying to argue is probably not a good idea.
Masking Labels
Back to my Universal-NER example, After tokenizing and simply copiying the input_ids, here are the labels input.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| token_ids | 2 | 256000 | 1645 | 108 | 1637 | 235292 | 1274 | 235292 | 109 | 2299 | 798 | 590 | 9825 | 970 | 11823 | 235336 | 256001 | 108 | 256000 | 105776 | 108 | 235285 | 235303 | 524 | 1682 | 736 | 2793 | 235265 | 256001 | 108 | 256000 | 1645 | 108 | 1841 | 19306 | 6815 | 575 | 573 | 2793 | 235336 | 256001 | 108 | 256000 | 105776 | 108 | 3681 | 45737 | 4437 | 256001 | 108 | 1 |
| tokens | <bos> | <|im_start|> | user | Text | : | Q | : | How | can | I | restore | my | Unity | ? | <|im_end|> | <|im_start|> | assistant | I | ' | ve | read | this | text | . | <|im_end|> | <|im_start|> | user | What | describes | software | in | the | text | ? | <|im_end|> | <|im_start|> | assistant | [" | Unity | "] | <|im_end|> | <eos> | |||||||||
| labels | <bos> | <|im_start|> | user | Text | : | Q | : | How | can | I | restore | my | Unity | ? | <|im_end|> | <|im_start|> | assistant | I | ' | ve | read | this | text | . | <|im_end|> | <|im_start|> | user | What | describes | software | in | the | text | ? | <|im_end|> | <|im_start|> | assistant | [" | Unity | "] | <|im_end|> | <eos> |
This seems a bit weird to me. In this example, the user is inputting the text Text: Q: How can I restore my Unity? and also What describes software in the text? and I’m expecting the model (the “assistant”) to only output ["Unity"]. So why should the model train on predicting all the user tokens if at inference, it will only be asked to generate the “assistant” tokens?
What I think we should do is, during training, ignore all “user-generated” tokens and let the model only learn to predict the “assistant” tokens of the conversation. This is done by setting the user tokens labels to -100. -100 is the default ignore_index in PyTorch’s CrossEntropyLoss, so when the loss function compares the output tokens with the labels, it will ignore all tokens labeled -100.
The same example as before but with ignore labels looks like (scroll to index 45):
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| token_ids | 2 | 256000 | 1645 | 108 | 1637 | 235292 | 1274 | 235292 | 109 | 2299 | 798 | 590 | 9825 | 970 | 11823 | 235336 | 256001 | 108 | 256000 | 105776 | 108 | 235285 | 235303 | 524 | 1682 | 736 | 2793 | 235265 | 256001 | 108 | 256000 | 1645 | 108 | 1841 | 19306 | 6815 | 575 | 573 | 2793 | 235336 | 256001 | 108 | 256000 | 105776 | 108 | 3681 | 45737 | 4437 | 256001 | 108 | 1 |
| tokens | <bos> | <|im_start|> | user | Text | : | Q | : | How | can | I | restore | my | Unity | ? | <|im_end|> | <|im_start|> | assistant | I | ' | ve | read | this | text | . | <|im_end|> | <|im_start|> | user | What | describes | software | in | the | text | ? | <|im_end|> | <|im_start|> | assistant | [" | Unity | "] | <|im_end|> | <eos> | |||||||||
| labels | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | I | ' | ve | read | this | text | . | <|im_end|> | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | -100 | [" | Unity | "] | <|im_end|> | -100 | -100 |
You can see now only “assistant” tokens get a label and the loss will ignore all the rest.
This is all nice, but does it really matter? So the model trained on some user tokens that it will never have to predict during inference, but is it that bad? Intuitively, I think it is. These models have a limited capacity for what they can learn, and at some point, for some datasets, it would be wasteful to get the model to learn to predict user tokens instead of assistant tokens. I chose the Universal-NER dataset because of the very high imbalance between user tokens and assistant tokens. In the previous example, most of the tokens are the user request, and only a tiny portion are assistant tokens the model should learn to predict.
To validate my intuition, I finetuned both approaches and compared their performance. In both cases, the validation loss ignored user tokens, so the numbers are comparable. Here are the results:
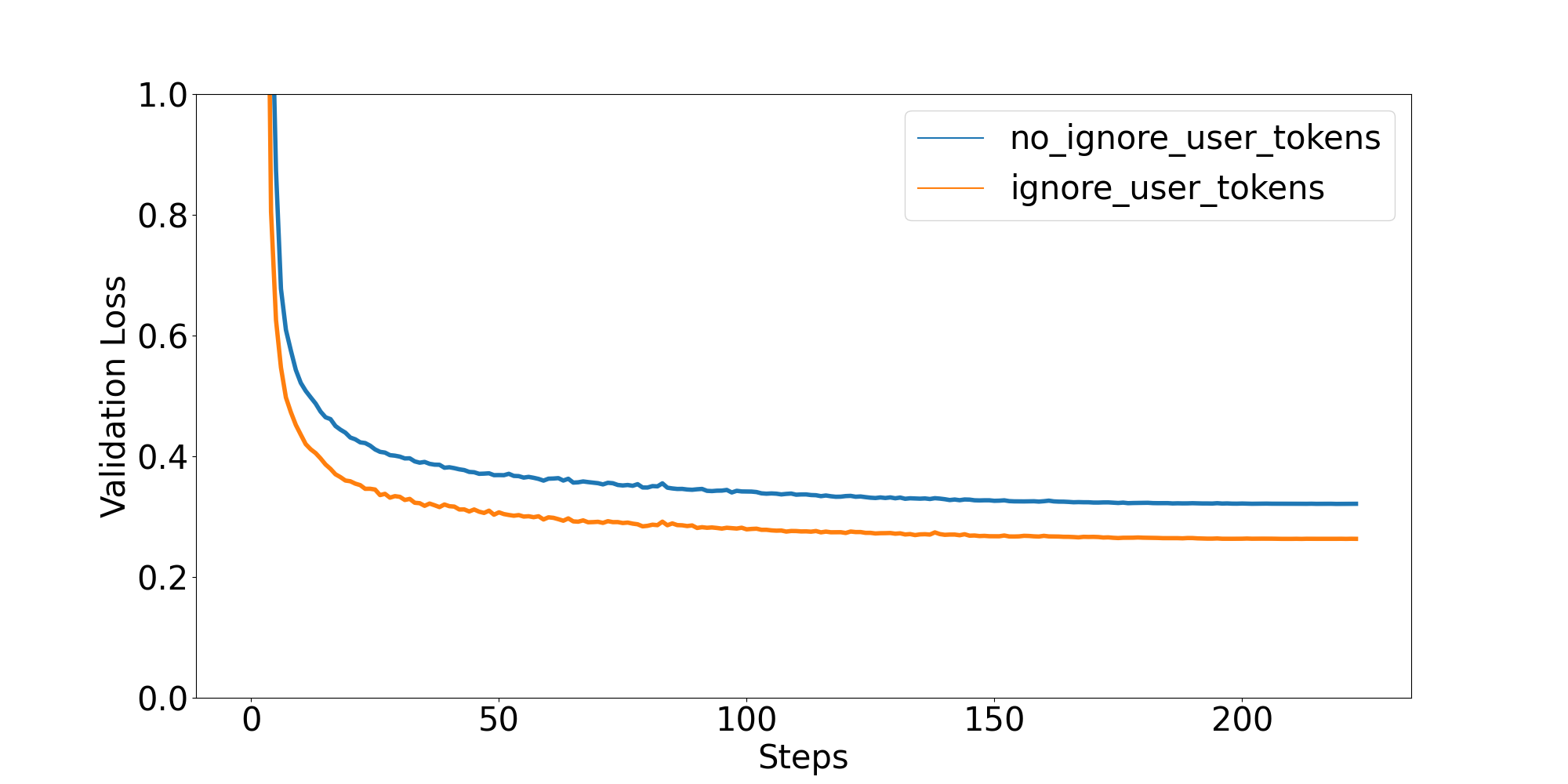
For Universal-NER, it seems better to mask user tokens, but is this true for other datasets? I did the same experiment with HuggingFaceH4/deita-10k-v0-sft. This is a more “classic” conversational dataset in that the assistant responses are longer than the user requests (by about a factor of 4). Here are the results:
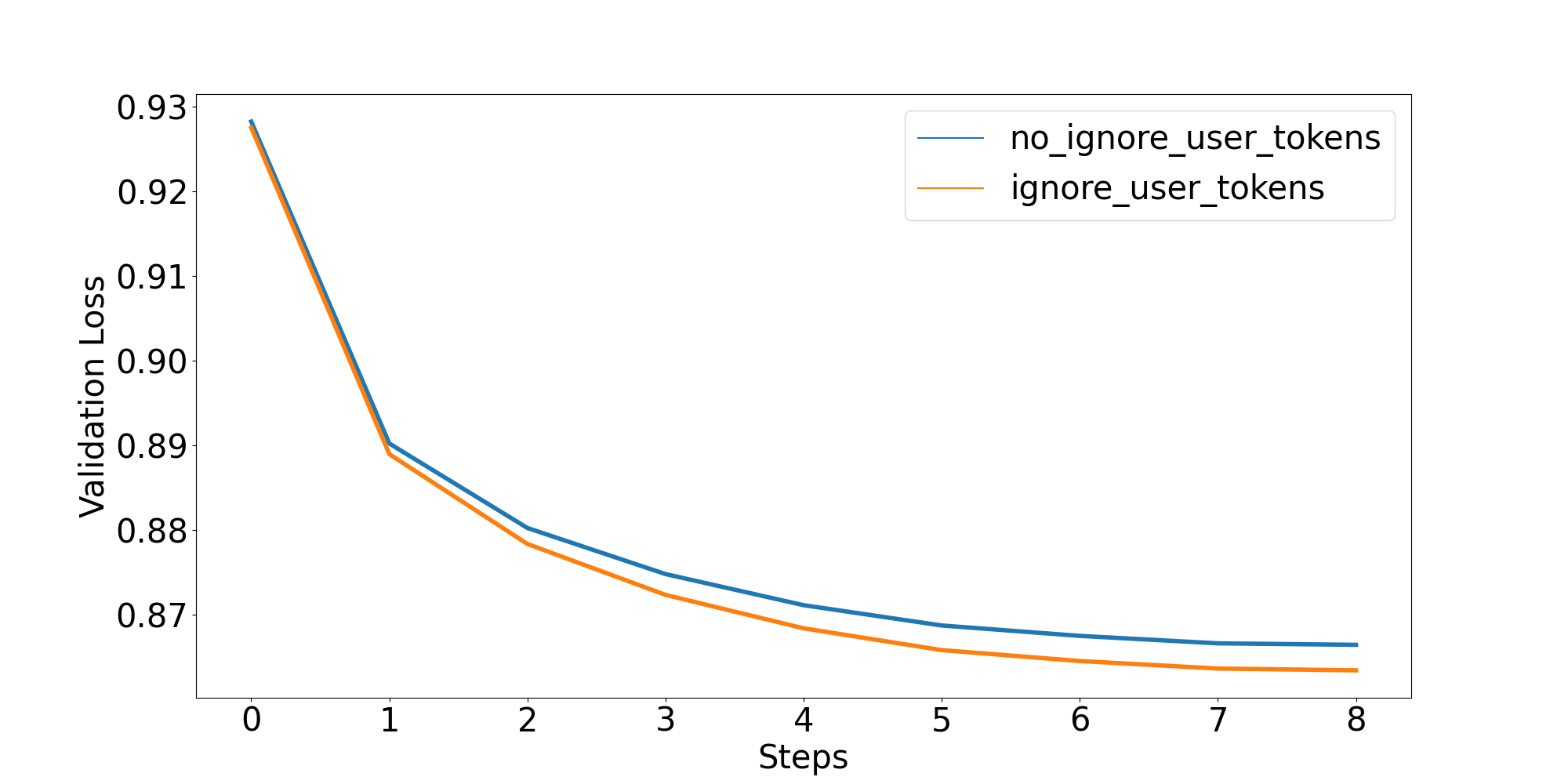 Again, masking seems to produce better results, although the difference in this case is much smaller.
Again, masking seems to produce better results, although the difference in this case is much smaller.
Conclusion
Intuitivly it seems to be better to mask user tokens, and the small experiments I have done also support my intuition. The next steps is to do full training on these datasetes and evaluate using other metrics than val_loss.
Also, never just use code on your data without really understanding what’s going on under the hood. No-code training projects like autotrain-advanced are amazing, but performance might not be as good as if you implemented the training yourself. By the way, AutoTrain also uses apply_chat_template, so they also don’t mask user tokens.