Extractive Question Answering with Generative Models
Generative models, such as ChatGPT and Llama2, excel in question-answering tasks given a specific context. For instance, consider the following prompt:
Given the following CT report, answer the question.
## REPORT
CT scan of the chest revealed the presence of multiple pulmonary nodules in the
upper and middle lobes of both lungs. Nodules are of varying sizes,
with the largest measuring approximately 4 mm.
Further evaluation and follow-up recommended to assess for any potential changes over
time.
## QUESTION
what is the location of the lung nodules
ChatGPT response is:
The CT report states that the pulmonary nodules are
located in the upper and middle lobes of both lungs.
Impressive! However, the practical application of this output isn’t always straightforward. For instance, when developing a medical application, physicians typically prefer direct references from the original text over a generative answer which might be inferred or “hallucinated”.
In such scenarios, what physicians are often looking for is known as “Extractive QA”. This method involves pinpointing an answer directly from the provided context and marking the start and end token locations within the text. In my example, it’s not possible to pinpoint the response location because the response string isn’t found verbatim in the context.
Typically, “Extractive QA” is achieved using encoder models like BERT. The output for each token indicates either the start or end of the answer, enabling us to pinpoint the exact location of the answer within the text.
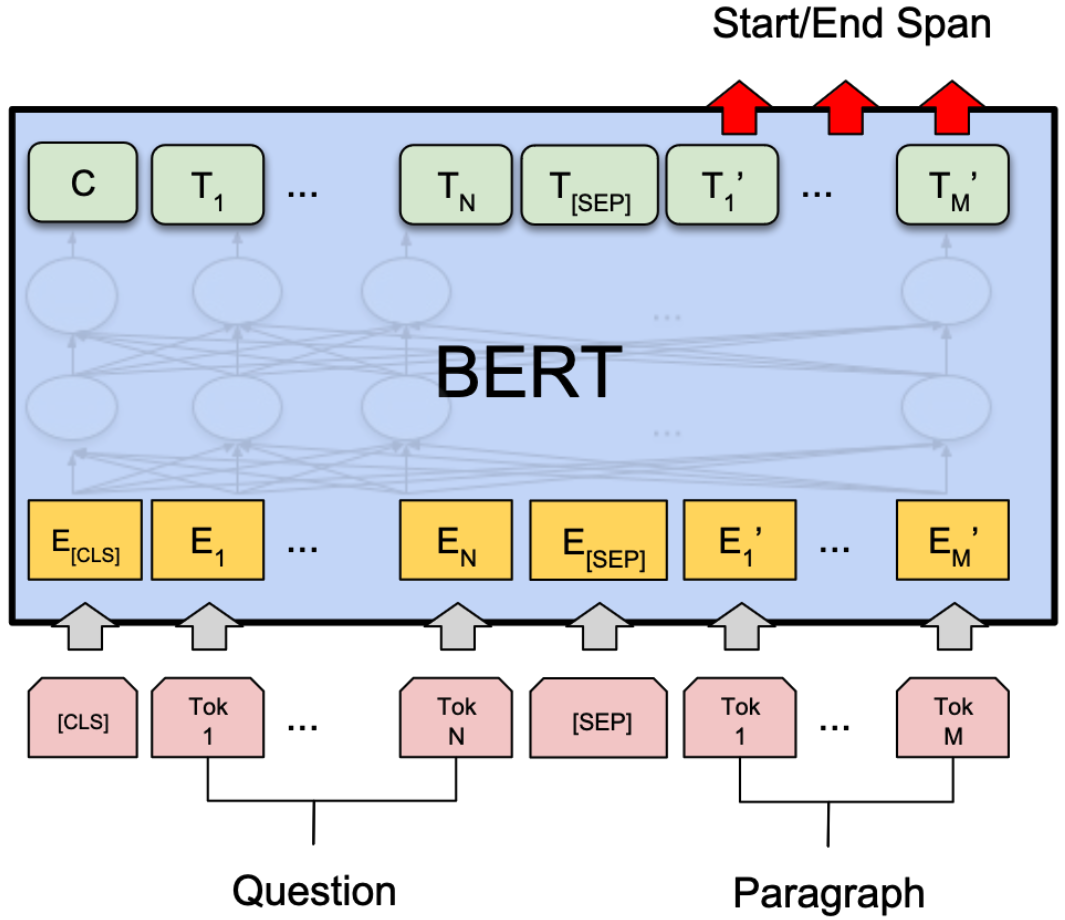
Inherently, outputting a start/end location of the answer is not possible with generative decoder models. These models are trained to predict the next word based on the preceding words. Despite having advanced models like llama2, trained to deeply understand and generate text, we can’t use them for what might appear to be a straightforward task: pointing to an answer within a given context.
A workaround some might consider is tweaking the prompt to encourage the model into providing an answer directly from the context. For instance, adding instructions such as “answer the question without rephrasing”.
While such strategies sometimes prove effective, I’d like to introduce a more robust solution: diving into the generation process. The goal here is to guide/constrain the model to output only a sequence of words present in the original context. So the output of the previous example would be:
upper and middle lobes of both lungs
This text can now be found in the original context with a simple string search.
Text Generation
Huggingface has a convenient interface called generate for text generation using autoregressive models. Users can set parameters like the maximum length of the generated text, specify end-of-sentence (eos) tokens, tweak beam search parameters, and much more.
Let’s take a look at how we can use the generate interface with our earlier mentioned CT report:
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto"
)
report = """
CT scan of the chest revealed the presence of multiple pulmonary nodules in the
upper and middle lobes of both lung. Nodules are of varying sizes,
with the largest measuring approximately 4 mm.
Further evaluation and follow-up recommended to assess for any potential changes over
time.
"""
template = """[INST] <<SYS>>
You are an AI that answers questions from medical reports.
<</SYS>>
Given the following CT report, answer the question without rephrasing shortest answer as possible.
## REPORT
{report}
## QUESTION
what is the location of the pulmonary nodules?[/INST]
"""
prompt = template.format(report=report)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, max_new_tokens=50, eos_token_id=tokenizer.eos_token_id)
And the assistent output is:
The location of the pulmonary nodules is in the upper and middle lobes of both lungs.</s>
Again, the model is correct but its not clear how I am supposed to find the location of the answer in the context.
Generation Process
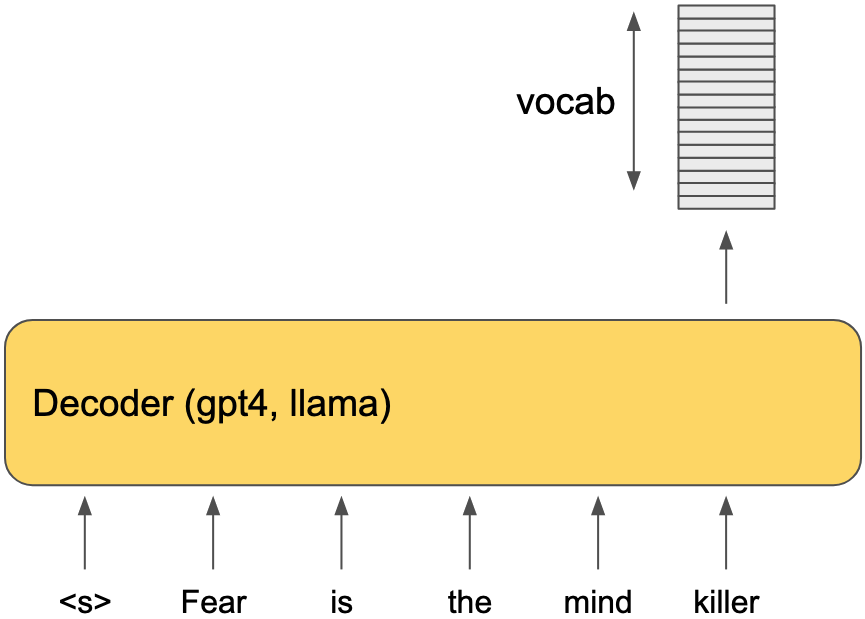
The generate function iterates until max_new_tokens is reached or the model generates an eos token. During each iteration, it performs a single forward pass using the currently generated string and selects the next word to add to the output. The next word is chosen by evaluating the output logits of the last token, which have a length equal to the vocabulary, and selecting the index with the highest value.
Here is an illustrated example:
Iteration 1

In this scenario, the index corresponding to “killer” is likely to have the highest value. As a result, generate will select “killer,” append it to the existing string, and initiate another iteration.
Iteration 2
To offer better control over the token selected during each iteration, Huggingface includes a useful parameter in the generate function called logits_processor. Users can provide a LogitsProcessor class to leverage this feature.
LogitsProcessor Interface
This convenient interface essentially serves as a callback that the generate function invokes after each iteration. Below is the signature for the __call__ method:
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
The generate function invokes this method, passing in the input_ids that were fed into the model during the current iteration and scores, which are the output logits of the last generated token. This method should return a modified scores tensor that generate will then use to choose the next token to append to the output.
A straightforward example of a LogitsProcessor is the MinLengthLogitsProcessor. What this processor does is simple: it examines the current length of the generated text. If the text has not yet reached the specified min_length, the processor sets all occurrences of eos_token_id in the scores tensor to negative infinity (-float("inf")). This ensures that an end-of-sequence token will not be chosen by generate at the conclusion of the current iteration.
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
cur_len = input_ids.shape[-1]
if cur_len < self.min_length:
for i in self.eos_token_id:
scores[:, i] = -float("inf")
return scores
It might be clearer now how to ensure the model’s output comes only from the given context—just set the score of any token not in that context to negative infinity (-float("inf")). However, simply letting generate choose tokens from the context isn’t enough; the entire sentence generated must also be a part of that original context.
Extractive Generation
I will now explain in detail how to force the greneration process to produce a string that is a substring of our context. Let’s take a look at a simple example using a report context:
the size of the nodule is 4mm and the location of the nodule is lungs. the nodule looks bad.
First Iteration
During the generate function’s first iteration, the model is tasked with generating the first word of the answer. Since this is the first generated word, it can be any word from the context. All we need to do is use a LogitsProcessor that, during the first iteration, sets the score of any token not present in the original context to -float("inf").
Let’s say the chosen word was “the”.
Second Iteration
Given that the first word of the answer is “the”, what words are we now allowed to generate? Only words that appear after the word “the” in the original context.
the size of the nodule is 4mm and the location of the nodule is lungs. the nodule looks bad.
We are only allowed to generate “size,” “nodule,” or “location,” so our LogitsProcessor will set all scores to -float("inf") except for the indices of “size,” “nodule,” and “location,” and let the generate function pick only the word with the highest score among these.
Let’s say the second word chosen is “nodule.”
Third Iteration
Our answer prefix is “the nodule”, so what words are we allowed to generate next? Only “is” and “looks,” so on this iteration our LogitsProcessor will set all scores to -float("inf") except for the indices of “is” and “looks.”
the size of the nodule is 4mm and the location of the nodule is lungs. the nodule looks bad.
This goes on until the model decides to stop with an eos token.
So all we need to do is keep track of the generated string—our prefix—and on each iteration, allow only the words that appear after this prefix in the original context to be generated. This can be done efficiently with a suffix tree.
The (partial) trie of suffixes that represent our example context looks like:
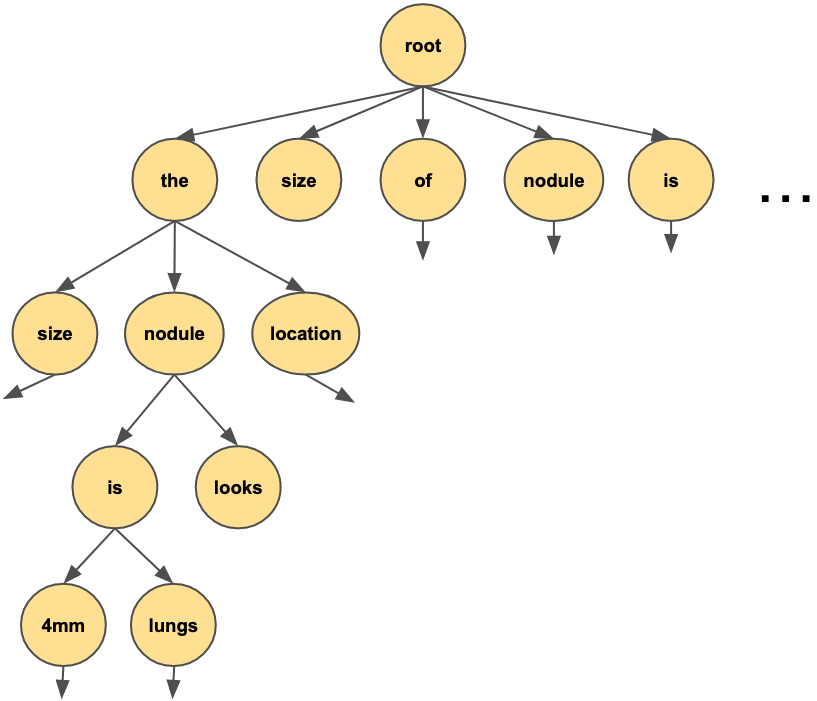
While generating the output sentence, we start at the root node and move down the tree. During each iteration, our LogitsProcessor will only allow words that are children of the current node.
In my simple example, we started at the root node, which points to all the words in the context. The word “the” was chosen, and it became the current node. In the second iteration, only the children of “the” were allowed, and as you can see in the image, these are only “size,” “nodule,” and “location.” This process continues in the same manner.
Simple Trie
There are many ways to implement a trie, but for this blog, I chose the simplest one I could think of: Each node in the tree is a python dictionary pointing to other dictionaries.
This function gets our tokenized context (list of tokens) and returns a trie of all its suffixes:
def create_trie(context_tokens: list[int]) -> dict[int, dict]:
trie = {}
for suffix in [context_tokens[i:] for i in range(len(context_tokens))]:
node = trie
for token in suffix:
if token not in node:
node[token] = {}
node = node[token]
return trie
Lets test this works:
trie = create_trie([1, 4, 3, 1, 4, 6])
print(trie[1][4].keys()) # walk down the path 1->4 and print the next options
> dict_keys([3, 6]) # works!
ExtractiveGeneration LogitsProcessor
Finally, it’s time to tie everything together in a single LogitsProcessor that will:
- Create a trie of suffixes from a given context.
- At each iteration, walk down the trie and edit
scoresto allow only words that make up a sentence from the original context.
Beam Search
When the generate function performs a beam search, our LogitsProcessor can’t keep track of all the locations in our trie for all the beams. So, our LogitsProcessor won’t maintain this state. Instead, during each iteration, we will walk down the tree with the current prefix and find the next word options. I use this tiny function to find the next token options in a trie given a prefix:
def valid_next_tokens(trie: dict[int, dict], prefix: list[int]) -> list[int]:
return list(reduce(lambda d, k: d.get(k,{}), prefix, trie).keys())
#check it works
trie = create_trie([1, 4, 3, 1, 4, 6])
print(valid_next_tokens(trie, [1, 4]))
> [3, 6]
And finally, here is my LogitsProcessor:
class ExtractiveGeneration(LogitsProcessor):
def __init__(self, input_start_len: int, context_tokens: list[int], eos_token_id: int | list[int]) -> None:
self.trie = create_trie(context_tokens)
self.input_start_len = input_start_len
self.eos_token_id = eos_token_id
if not isinstance(self.eos_token_id, list):
self.eos_token_id = [self.eos_token_id]
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
beam_prefixes = input_ids[:, self.input_start_len :]
for i, prefix in enumerate(beam_prefixes):
options = valid_next_tokens(self.trie, prefix.tolist())
options.extend(self.eos_token_id)
options = torch.tensor(options, dtype=torch.int, device=input_ids.device)
mask = torch.isin(torch.arange(scores[i].numel(), device=input_ids.device), options)
scores[i][~mask] = float("-inf")
return scores
The __init__ function receives the length of the input so that, during generation, I can ignore the original input and focus only on the generated part of input_ids. It also receives context_tokens, which is the tokenized context, and eos_token_id, which are the end-of-sentence tokens that will be allowed during generation.
The class will create a trie from the context_tokens and save both the input_start_len and eos_token_id for later use.
The __call__ steps:
input_idscontains the whole input to the model during the current iteration. Since I’m only interested in the generated part and not the original prompt, the first thing I do is computebeam_prefixes. This is done by cutting offinput_idsfrom index 0 toinput_start_len, leaving us with the generated prefix of each beam.- Next, for each beam, I call
valid_next_tokenswith the current prefix to compute the valid next words for that beam. I then add the eos_tokens as valid tokens, and finally set allscoresto-infexcept for the valid words.
No lets see this in action:
inputs = tokenizer.encode(prompt, return_tensors="pt").to("cuda:0")
lp = ExtractiveGeneration(inputs.shape[-1], tokenizer(report)["input_ids"], tokenizer.eos_token_id)
lp = LogitsProcessorList([lp])
response = model.generate(
tokenizer.encode(prompt, return_tensors="pt").to("cuda:0"),
max_new_tokens=100,
eos_token_id=tokenizer.eos_token_id,
logits_processor=lp,
num_beams=3,
)
print(tokenizer.decode(response[0,inputs.shape[-1]:]))
And the response…
upper and middle lobes of both lungs
Yes! The text can be easily pinpointed within the original context by a simple string search.
Summary
I’ve shown in this post how to force the generation process to produce sentences that appear exactly in a specific context. This doesn’t guarantee that the answer is necessarily correct, but whatever I generate is 100% a substring of the context.